New NER Toolchain and Demo
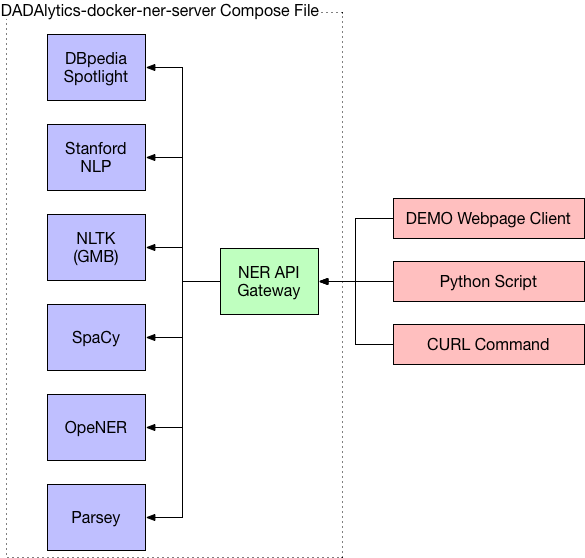
As part of our IMLS-funded DADAlytics project we are evaluating Named Entity Recognition (NER) tools and their performance on cultural heritage materials. The identification of entities within textual resources is the first step in a larger process of converting textual documents into a linked open dataset. Within the context of natural language processing, NER is a well-researched area and there are several tools available for use. While working with these tools for our own research, we sensed the steep learning curve could be a barrier to use. This inspired us to develop a data service that would make it easier to use and make the most of some of the existing tools. One deliverable from this process is a streamlined NER toolchain that uses six natural language processing tools. We have compiled these tools into a single dockerized server that can be used to perform named entity extraction on text. “Dockerizing” these tools into a single application with an API greatly reduces the difficulty in setting up the software and enables quickly getting started with NER.
The tools used are:
- DBpedia Spotlight
- Stanford NLP (using the english.muc.7class.distsim.crf.ser.gz classifier)
- NLTK trained on the Groningen Meaning Bank corpus
- SpaCy
- The OpeNER Project
- Tensorflow SyntaxNet: Parsey McParseface (POS tagger used to extract proper nouns)
Each tool has been dockerized or an existing docker image has been used and combined into a single server image with an API to process text through each tool.
These tools were selected because they were the best free/open source NER/NLP tools available. If you think there is another tool we should be utilizing, please let us know.
For a demo of this server visit: https://ner.semlab.io

This demo allows you to input text and select which tool(s) to use for analysis. It also shows how you can perform this task programmatically via the API.
If the server is down, click the “Spawn Server” button and it will launch the demo. It will relaunch in about five minutes.
This site acts as the client to the gateway that combines the results from the multiple NER tools into a single API:
The API will return combined results of the text analyzed using the tools you specified. For example, here is the data returned for an entity found in text submitted:

text: The text of the entity
type: The type of entities the tools marked it as (here it found it four times as a personal name)
tool: The tools that detected the entity
confidence: The number of tools that detected it divided by the number of tools used, 4/4 found this entity, so 100%
typeMode: The average mode of the entity type. This is useful because it gets the most likely entity type based on all the tools tagging. If an entity was flagged as a person 4 times and a organization 2 it would be “per”
spotlightUri: If the spotlight tool detects an entity it will also give the DBpedia resource URI
About the tools:
- Stanford NLP - A packaged up version of the tool with a Node API, docker image.
- NLTK - Trained on the Groningen Meaning Bank corpus with a Node API, docker image.
- OpeNER - A toolchain that contains NER as one part of the process, with a Node API server docker image.
- SpaCy - A NLP tool that includes NER, used existing image.
- Tensorflow SyntaxNet: Parsey McParseface - This is not a NER tool, but a part of speech tagger that we used to try and extract proper nouns. Used existing image.
- DBpedia Spotlight - an NER tool based on Wikipedia corpus, it detects entities and provides the DBpedia resource that it matched to. Used existing image.
If you know of other NER tools that would be useful to be included, please drop us a line at semanticlab@pratt.edu.
Running
To run this service yourself you only need to have Docker and Docker-Compose installed, if you do you run:
git clone https://github.com/SemanticLab/DADAlytics-docker-ner-server.git
cd DADAlytics-docker-ner-server
docker-compose up
These tools take a lot of RAM to function, so you would need to have around 16-20GB of RAM to run all of them. You can also edit the docker-compose.yml file to only run specific tools.
You can also install this on a temporary server from a provider like Digital Ocean or Amazon’s AWS. Here is a quick tutorial on running it on an Ubuntu Linux system.
Server Tutorial
I’m going to use Digital Ocean (http://digitalocean.com/) and spin up a server with enough RAM. I’m going to use one running Ubuntu 16.04.4 x64 with 32GB of RAM.
SSH to the server
ssh root@159.89.42.6
And use the password emailed to me by DO.
I’ve compiled the commands that do everything we need to get the server up and running: Setup swap space:
sudo mkdir -p /var/vm
sudo fallocate -l 20000m /var/vm/swapfile1
sudo chmod 600 /var/vm/swapfile1
sudo mkswap /var/vm/swapfile1
sudo echo -e "[Unit]\nDescription=Turn on swap\n[Swap]\nWhat=/var/vm/swapfile1\n[Install]\nWantedBy=multi-user.target" > /etc/systemd/system/var-vm-swapfile1.swap
sudo systemctl enable --now var-vm-swapfile1.swap
Install Docker:
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
sudo apt-get update
sudo apt-get install -y docker-ce
Install Compose and the NER Gateway App:
sudo mkdir -p /opt/bin
sudo curl -L "https://github.com/docker/compose/releases/download/1.14.0-rc1/docker-compose-$(uname -s)-$(uname -m)" -o /opt/bin/docker-compose
sudo chmod +x /opt/bin/docker-compose
sudo mkdir -p /etc/certs; sudo chown nobody:nogroup /etc/certs; sudo chmod 755 /etc/certs;
sudo git clone https://github.com/SemanticLab/DADAlytics-docker-ner-server.git /home/core/DADAlytics-docker-ner-server
sudo chown nobody:nogroup /etc/certs -R; sudo chmod 755 /etc/certs -R
OSX Tip: @hadro reported this process works for OSX as well but need to change the certs directory to /private/etc/certs:/etc/certs in the composer file and sudo mkdir /private/etc/certs to make the directory.
Now we can run it:
cd /home/core/DADAlytics-docker-ner-server/
/opt/bin/docker-compose up
This will launch the services and the API. It takes a few minutes for things to spin up, and the DBpedia Spotlight will take a few more moments to load all the resources into memory.
Once that is complete you can use the API from anywhere, on your local machine:
curl -H "Content-Type: application/json" -X POST -d '{"text":"The term anti-art, a precursor to Dada, was coined by Marcel Duchamp around 1913 to characterize works which challenge accepted definitions of art.","tool":["spacy","parsey","nltk","stanford","opener","spotlight"]}' http://159.89.42.6/compiled
You can keep the server running in the background with:
/opt/bin/docker-compose up -d
Don’t forget to destroy the Digital Ocean droplet once you are finished, costs can add up quickly with a large server. And there are options in the compose file to enable SSL if you have a domain name.
As we continue to build this toolchain we will release other modularized components which hopefully can be useful to the community as well.