Communicating Ontology
Technical approaches for facilitating use of our Wikibase data
Matt Miller | 05 March 2025
Communicating Ontology
Technical approaches for facilitating use of our Wikibase data
Matt Miller | 05 March 2025
Our work at Semantic Lab is broken into many different projects. These projects cover a large range of topics with domains in jazz, art history and more. We organize all of our project data in a single Wikibase system running at base.semlab.io. Wikibase, which is the software that runs Wikidata, works on defining an ontology to structure your data. The Semlab team has spent a lot of effort thoughtfully creating an ontology that maximizes reuse of properties and classes across our multiple projects. But any sort of ontology that is robust enough to support our work will likely be confusing to newcomers. This post is going to look at a few of the technical solutions we’ve implemented to communicate our ontology to a new audience.
The first avenue into a Wikibase installation for someone wanting to understand its data will likely be keyword searching across the database. This will get you to Item pages and you can see the properties and values defined. But once you begin asking specific questions of the data you will need to think about how to format your question into a SPARQL query. We run a SPARQL query endpoint at query.semlab.io which provides the means to query our data but just getting started is a fairly high bar.
To begin you need to know how to write SPARQL, which is a query language with its own rules for syntax and structure, a skill which is reusable from other SPARQL endpoints such as Wikidata. But you also need to know what properties and item identifiers you are going to use to write the query. This is domain-specific knowledge: knowing the exact QIDs (Items) and PIDs (Properties) to write into your query. One way to gain this understanding is by looking at the Item pages, you find the thing you are interested in and look at the properties that are used and then extrapolate that to write your query. This works okay but you are at the item level where you only are seeing one example of how the ontology is used, to write queries you need to understand how it is used across the system. Knowing at a global level how these properties are used across all items and how complete the data is would allow you to communicate your question in SPARQL effectively.
To facilitate this higher level of understanding of our properties' and items' usage we’ve developed a tool called Property Explorer to help visualize these relationships:
This tool builds a visual interface for our over 200 properties used in the Wikibase and summarizes how they are used by describing the type of items they connect. Let’s look at an example, P75 contributor:
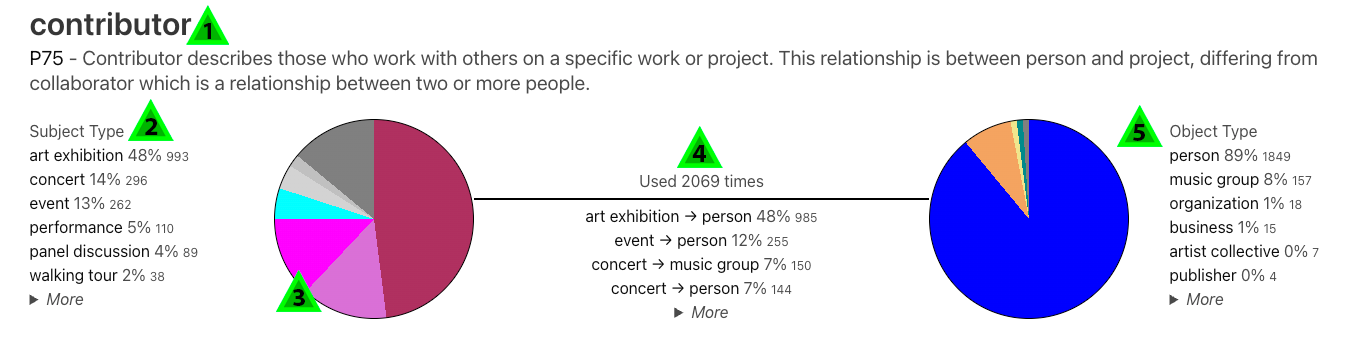
Let’s go through the information for each property, I’ve numbered the different parts of the interface in green triangles:
There is also at the top of the page the ability to filter the properties by specific criteria. You can limit the properties displayed based on the project its subjects and objects are part of, the type of subjects and the type of objects. So for example, if you were interested in the people of the Linked Jazz project you can filter by the Linked Jazz Oral History project with people as the subject and people as the object. If you apply these filters, you would see that there are only 31 properties out of the 200+ that match. This would provide you with the info you would need to start writing queries to explore the people of Linked Jazz.

The Property Explorer’s data is updated every night via a job that runs on the server and then publishes the data to a Github repository which has its interface hosted on Github pages in the same repo. You can check out the underlying data and code at github.com/SemanticLab/property-explorer.
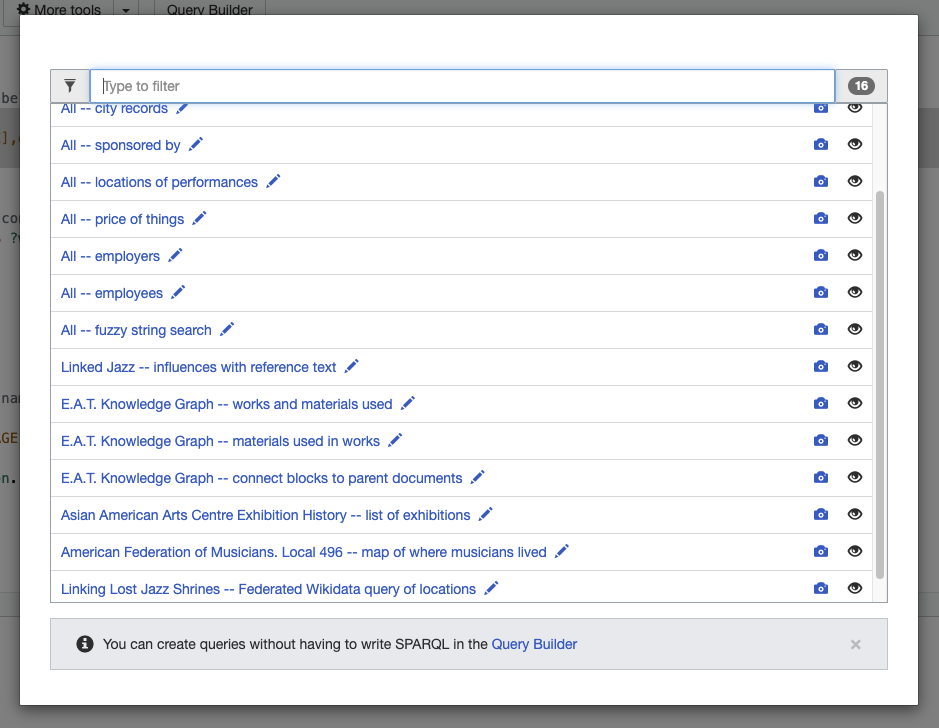
The next step is actually writing your SPARQL query. Armed with the info gained above you can jump into writing a query at query.semlab.io from scratch. But it is always easier to edit something than start from a blank slate. The Wikibase software lets you define canned SPARQL queries that can be loaded as examples in the query interface. We are taking advantage of this feature and populating example queries when we are able. On the query interface page you can hit the Examples button and see the ones we have so far:
The final tool I want to look at is our data export processes. Writing queries works well for targeted questions and exploration but if you wanted to programmatically work with the data to build a visualization or apply some analytical or machine learning process you would want the whole corpus. The issue in my mind for these use cases is of course the audience and expertise, meaning you want to make the data as useful for as many people as possible. The issues with just providing a data dump of the triple store that powers the query interface is that the native RDF Wikibase data model is necessarily complicated and then on top of the data model is our ontology, the QIDs and PIDs. You can see a diagram here but it is a very high bar to work with. We do provide an RDF dump of the system for the brave that would like to use our data in that form. But we also provide the data in a much more simplified JSON-LD format.
github.com/SemanticLab/data-export
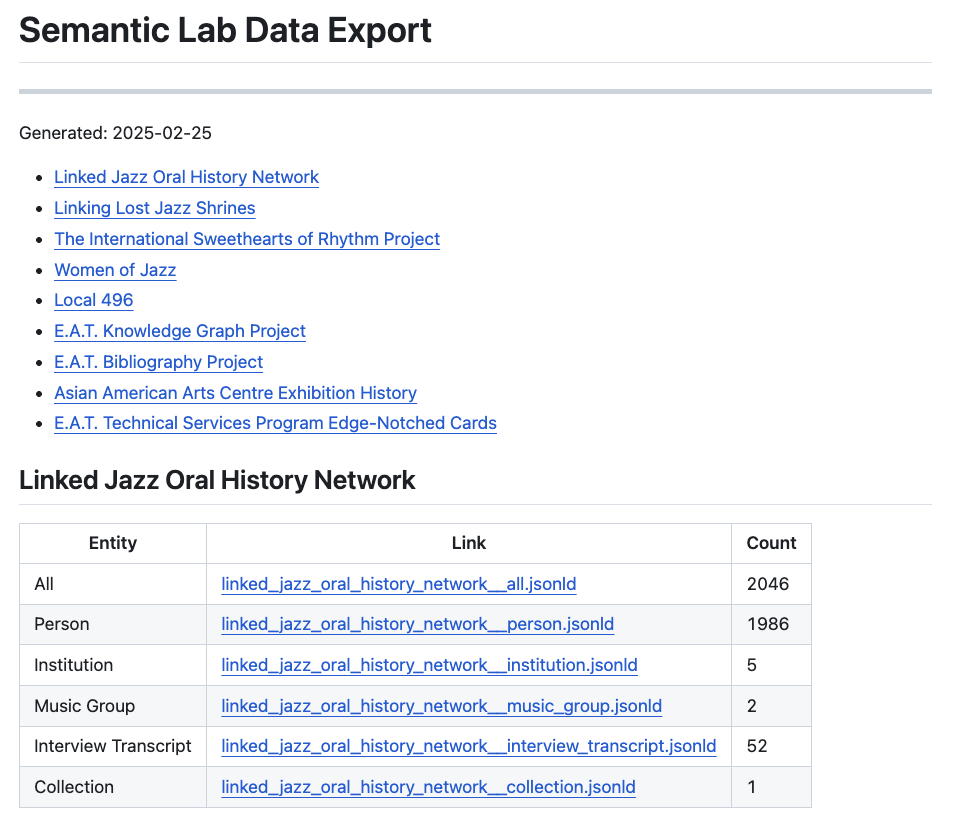
The data dumps provided are broken into projects and then by entity. You can of course grab all the data for a specific project but if you are only interested in the People of Linked Jazz there is a three megabyte file with everything you need. Here is an example of the simplified data for a single Person: Mary Lou Williams. We also use the JSON-LD context feature to create simple aliases for the property and item URIs. You can see our context file here. So instead of a very long http://base.semlab.io/entitiy/blah URI for every single thing you have simple, human readable words and phrases for the data keys. This much more approximates the experience programers would have with non-linked data datasets. The organization of these specific data dumps also makes small changes to where things are aggregated and other differences that make working with the data easier. Ultimately we hide a bit of the ontology’s complexity behind aliases and organization to provide a better experience but the important aspects that make the data “linked data” are still present and actionable. Like the Property Explorer, these data dumps are generated every night, and you can view the data and source code that generates them at the link above.
The content of the projects at Semlab are of course the most compelling aspect of our work, from revealing the social relationships of jazz musicians to mapping the collaborations of the Experiments in Art and Technology (E.A.T.) movement. But for us how that work is done and organized and accessed is equally compelling. This question of knowledge organization and communication is a central component to the Semantic Lab project as a whole and a driver for the types of experiments discussed in this post.